Attention is all you need… and maybe a bit of patience with AWS.
My Journey with Distilled BERT on AWS SageMaker
Warning: this is gonna be a long one, so hang in for the ride and buckle up.
I started this project for two main reasons: first, I wanted to get my hands dirty with AWS Cloud and really understand what it takes to run machine learning at scale. Second, I wanted to explore how you can actually train a fairly large model on a real dataset — not just a toy problem that fits on your laptop.
The idea was simple: if I could train and deploy a model like Distilled BERT on AWS SageMaker, I’d learn both about modern NLP architectures and about the nitty-gritty of cloud-based machine learning. Spoiler: it wasn’t always smooth sailing, but it was worth it.
In the rapidly evolving landscape of Artificial Intelligence, Natural Language Processing (NLP) stands out as a field brimming with transformative potential.
My recent endeavor into this domain involved a fascinating project: training a sophisticated language model on AWS SageMaker, a powerful cloud-based machine learning platform. This journey not only deepened my understanding of cutting-edge NLP architectures but also provided invaluable hands-on experience with cloud infrastructure, highlighting the symbiotic relationship between advanced AI and scalable computing.
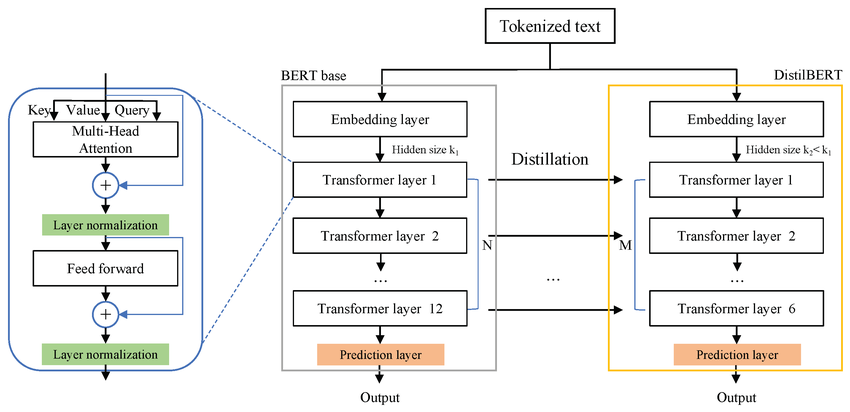
At the heart of this project was Distilled BERT, a streamlined yet highly effective variant of the groundbreaking BERT (Bidirectional Encoder Representations from Transformers) model. BERT revolutionized NLP by introducing a novel approach to pre-training language representations, allowing models to understand context from both left and right of a word simultaneously. Distilled BERT takes this innovation a step further, offering a more efficient alternative without significant performance compromise. This choice was deliberate, reflecting a growing industry trend towards optimizing models for real-world deployment where computational resources and inference speed are critical considerations.
Text classification, the primary application of this project, is a cornerstone of modern data processing and AI-driven decision-making. Its importance cannot be overstated, as it underpins a multitude of practical applications that enhance efficiency and user experience across various sectors. Consider the daily deluge of information: news articles, emails, social media posts, and customer feedback. Without effective classification, navigating this data would be an insurmountable task. For instance, in news categorization, text classification automatically sorts articles into relevant topics like ’Business,’ ’Technology,’ or ’Entertainment,’ making information retrieval faster and more accurate. Similarly, spam filters rely on text classification to identify and quarantine unwanted emails, safeguarding inboxes from clutter and malicious content. Beyond these, sentiment analysis, a specialized form of text classification, gauges the emotional tone behind text, providing businesses with critical insights into customer satisfaction and brand perception. These examples merely scratch the surface, demonstrating how text classification empowers systems to understand, organize, and react to human language at scale, transforming raw data into actionable intelligence.
This blog post will delve into the intricacies of this project, exploring the rationale behind choosing Distilled BERT, dissecting the foundational Transformer architecture, examining the dataset used, and sharing the practical insights gained from leveraging AWS SageMaker.
My aim is to provide a comprehensive overview that balances technical depth with accessibility, offering valuable perspectives for anyone interested in the practical application of NLP and cloud-based machine learning.
The Power of Efficiency: Understanding Distilled BERT and the Transformer Architecture
In the realm of large language models, the original BERT model marked a significant milestone, demonstrating unprecedented capabilities in understanding contextual nuances of language. However, its sheer size and computational demands often posed challenges for deployment in resource-constrained environments or applications requiring rapid inference. This is where Distilled BERT emerges as a compelling solution. Distilled BERT is a smaller, faster, and lighter version of BERT, meticulously designed to retain a substantial portion of its parent model’s performance while drastically reducing its computational footprint. This efficiency is achieved through a process called knowledge distillation, where a smaller model (the student) is trained to mimic the behavior of a larger, more complex model (the teacher).
The advantages of Distilled BERT are manifold. Its reduced size translates directly into faster inference times, making it ideal for real-time applications such such as chatbots, search engines, or mobile devices where latency is a critical factor. Furthermore, its lower memory and computational requirements mean it can be deployed on less powerful hardware, including edge devices or within cloud environments where cost optimization is paramount. This makes Distilled BERT a superior choice over the original BERT in scenarios where efficiency and speed are prioritized without a significant compromise on accuracy. For instance, in cloud-based services, using Distilled BERT can lead to substantial savings in operational costs due to lower GPU utilization and faster processing. On devices with limited capacity, it enables sophisticated NLP capabilities that would otherwise be impossible.
Distilled BERT vs. BERT: A Comparative Glance
To appreciate Distilled BERT’s ingenuity, it’s helpful to briefly compare it with its predecessor:
Feature | BERT (Base) | Distilled BERT |
Architecture | 12 layers, 768 hidden size, 12 attention heads | 6 layers, 768 hidden size, 12 attention heads |
Parameters | ~110 million | ~66 million |
Size | Larger, more resource-intensive | Smaller, more efficient |
Speed | Slower inference | ~60% faster inference |
Accuracy | High | ~97% of BERT’s performance on GLUE benchmark |
Resource Needs | High computational power, significant memory | Lower computational power, reduced memory |
As evident from the table, Distilled BERT achieves its efficiency primarily by having fewer layers in its Transformer encoder stack. While BERT utilizes 12 encoder layers, Distilled BERT typically employs 6. Crucially, it maintains the same hidden size and number of attention heads, allowing it to preserve much of the representational capacity that makes BERT so powerful. This balance of efficiency and performance is what makes Distilled BERT a highly attractive option for many real-world NLP applications.
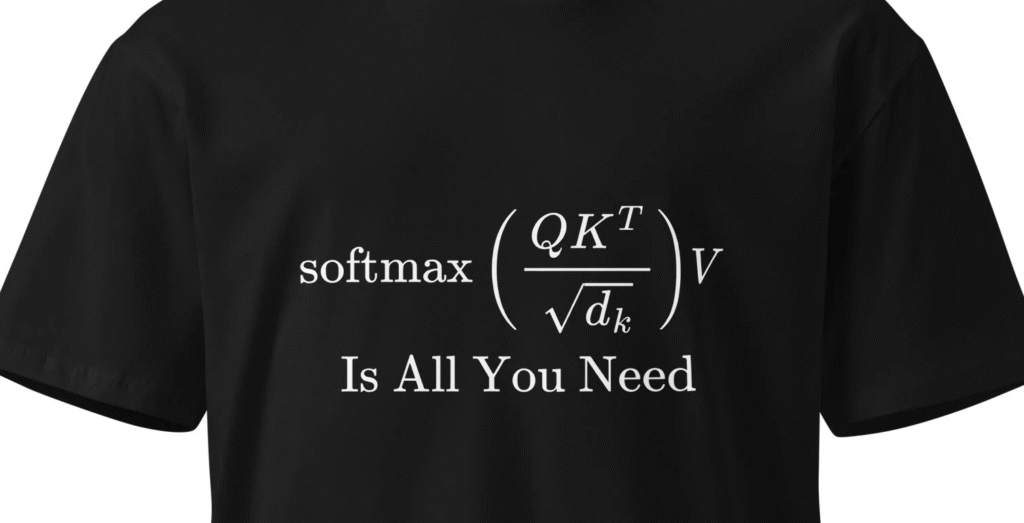
Transformers and ”Attention Is All You Need…”
Of course, none of this would exist without the paper that kicked off the whole Transformer revolution: “Attention Is All You Need” by Vaswani et al. (2017).
This paper basically said: Hey, forget RNNs, forget CNNs — let’s just use attention mechanisms. That simple yet radical idea allowed models to process entire sequences in parallel, handle long-range dependencies, and scale up in ways that were unthinkable before.
If there’s one paper in NLP you should read (or at least skim), it’s that one. Honestly, BERT, GPT, Distilled BERT, you name it — they all trace back to this. Without that shift in thinking, large language models as we know them today wouldn’t exist.
The Foundation: Understanding the Transformer Architecture
Both BERT and Distilled BERT are built upon a revolutionary neural network architecture known as the Transformer. Introduced in the seminal paper ”Attention Is All You Need” by Vaswani et al. in 2017 [1], the Transformer moved away from traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) for sequence processing, relying entirely on a mechanism called self-attention. This shift allowed for unprecedented parallelization during training, significantly speeding up the development of large language models.
At its core, the Transformer processes input sequences (like sentences) by first converting each word into a numerical representation called an embedding. These embeddings capture semantic meaning, where words with similar meanings are located closer to each other in a multi-dimensional space.
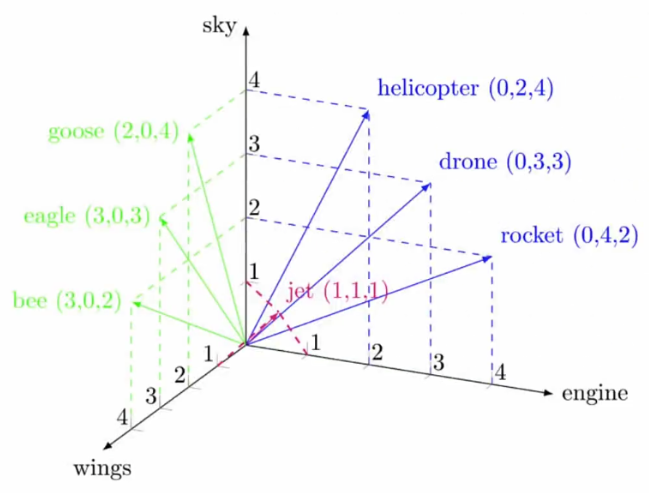
For example, in a simplified 3D space with axes like ’sky’, ’wings’, and ’engine’, words like ’goose’, ’eagle’, and ’bee’ might cluster together due to their shared ’wings’ and ’sky’ attributes, while ’helicopter’, ’drone’, and ’rocket’ form another cluster based on ’engine’ and ’sky’ characteristics. A word like ’jet’ might sit somewhere in between, sharing attributes with both groups. This spatial representation allows the model to understand relationships between words based on their contextual similarities.
However, simply converting words to embeddings loses a crucial piece of information: their position in the sentence. Unlike RNNs that process words sequentially, Transformers process all words in a sentence simultaneously. While this parallelization is a major advantage for speed, it means the model inherently loses information about word order. For instance, the sentences ”The dog chased the cat” and ”The cat chased the dog” contain the same words but convey entirely different meanings due to their arrangement. To address this, Transformers employ Positional Encoding.
Positional encoding adds a unique numerical vector to each word’s embedding based on its position in the sequence. This way, even though words are processed in parallel, the model still receives information about the relative or absolute position of each word. The original Transformer paper utilized sine and cosine functions of different frequencies to generate these positional encodings, creating a unique pattern for each position that the model can learn to interpret.
The Self-Attention Block: How Transformers Understand Context
The true magic of the Transformer architecture lies in its Self-Attention Block. This mechanism allows the model to weigh the importance of different words in the input sequence when processing each word. Instead of relying on a fixed window or sequential processing, self-attention dynamically determines how much ’attention’ to pay to other words in the sentence to better understand the current word’s meaning.
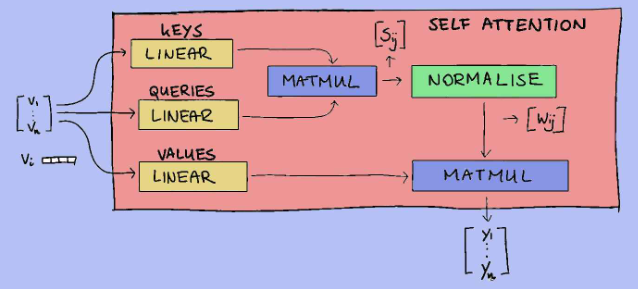
The process within a self-attention block can be broken down into several key steps:teps:
1.Input Tokens and Embeddings: The journey begins with the input sequence of words (tokens). Each token is converted into a numerical vector, its embedding, which captures its semantic meaning. These embeddings are the raw material for the self-attention mechanism.
2.Query (Q), Key (K), and Value (V) Generation: For each word embedding, three distinct vectors are created: a Query (Q), a Key (K), and a Value (V). These are generated by multiplying the original embedding with three different weight matrices (Linear transformations). Think of them as:
- Query (Q): Represents the current word for which we are trying to find relevant information. It’s like asking, ”What am I looking for?”
- Key (K): Represents the words in the sequence that we are comparing against the query. It’s like asking, ”What do I have that might be relevant?”
- Value (V): Contains the actual information or content of the words that will be aggregated based on the attention scores. It’s like saying, ”Here’s the information if you need it.”
3.Calculating Scores (Matmul): The Query vector of the current word is multiplied (dot product) with the Key vectors of all other words in the sequence (including itself). This matrix multiplication (Matmul) yields a score (sᵢᵢ) for each word pair, indicating how relevant each word is to the current word. A higher score means greater relevance.
4.Normalizing Scores (Normalize/Softmax): These raw scores are then passed through a normalization function, typically a softmax function. This converts the scores into probabilities, or ”attention weights” (wᵢᵢ), ensuring they sum up to 1. These weights quantify how much attention the current word should pay to every other word in the sequence.
5.Combining Values (Matmul): Finally, these attention weights are multiplied with the Value vectors of all words. The weighted Value vectors are then summed up. This second matrix multiplication (Matmul) effectively combines the information from all words in the sequence, giving more prominence to words that received higher attention weights. The result (vᵢᵢ) is a new representation for the current word that is enriched with context from the entire sentence.
6.Linear Transformation and Output: The combined value vector then undergoes a final linear transformation to project it into the desired output dimension, ready to be passed to the next layer of the Transformer. This output is a context-aware representation of the original word.
This entire process, from input embeddings to the context-rich output, forms the self-attention block. By repeating this process across multiple ”attention heads” (as discussed in the previous presentation slide), the model can learn to focus on different types of relationships simultaneously – some heads might capture syntactic dependencies, while others focus on semantic connections or long-range dependencies. This multi-faceted attention mechanism is what gives Transformers their remarkable ability to understand complex language patterns.
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30. https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
The Cloud Part: Necessary Evil or the Best Thing Since Sliced Bread?
Now, let’s talk about the cloud. AWS, Google Cloud, Azure — they all promise the moon and stars. And yes, the cloud is powerful. I wouldn’t have been able to run this project on my laptop unless I wanted it to melt into a puddle. At its essence, cloud computing refers to the delivery of on-demand computing services—including servers, storage, databases, networking, software, analytics, and intelligence—over the Internet (”the cloud”). Instead of owning your own computing infrastructure or data centers, you can access these services from a cloud provider, paying only for what you use. This model offers unparalleled agility, elasticity, and cost-effectiveness, making it a game-changer for businesses and researchers alike.
But let’s keep it real: the cloud isn’t all rainbows.
- Costs creep up fast. What starts as “a few dollars an hour” can suddenly balloon into something that makes your credit card sweat.
IAM headaches. AWS’s Identity and Access Management system can make you feel like you need a PhD just to give a notebook permission to access a bucket.
Vendor lock-in. The more you use their tools, the harder it gets to move away.
Less control. You’re renting someone else’s servers. When AWS has an outage, so do you.
So yes, the cloud is amazing. It’s also frustrating. It’s both the best enabler and the biggest bottleneck depending on the day.
The global cloud computing market is dominated by a few major players, each offering a comprehensive suite of services. The three largest and most influential are:
1.Amazon Web Services (AWS): The pioneer and long-standing market leader, offering the broadest and deepest set of services.
2.Microsoft Azure: A strong contender, particularly popular among enterprises already invested in Microsoft technologies.
3.Google Cloud Platform (GCP): Known for its strengths in data analytics, machine learning, and open-source technologies.
Conclusion: Lessons Learned and the Road Ahead
This project, focused on training a Distilled BERT model on AWS SageMaker for text classification of news articles, has been an incredibly enriching experience. It provided a holistic view of a real-world machine learning pipeline, from understanding the nuances of data to deploying a sophisticated model in a cloud environment.
Through this endeavor, I gained practical insights into model architecture, effective data handling strategies, and the critical role of cloud computing in modern AI development. One of the most significant takeaways has been the profound importance of understanding Transformer models. While the underlying mathematics can be complex, grasping the core concepts of self-attention and positional encoding is paramount for anyone working in contemporary NLP. Even without delving into every single mathematical derivation, having a solid conceptual understanding of how these mechanisms allow models to process and comprehend language has been transformative. It demystifies the ’black box’ somewhat, enabling more informed decisions during model selection, fine-tuning, and troubleshooting.
The elegance and power of the Transformer architecture, particularly its ability to capture long-range dependencies and parallelize computations, truly underscore why it has become the backbone of state-of-the-art NLP. Furthermore, this project underscored the immense value of practical cloud skills. Leveraging AWS SageMaker not only facilitated the training of a large language model but also provided invaluable experience with the broader cloud ecosystem. Navigating the complexities of AWS, from setting up SageMaker instances to configuring IAM roles, highlighted that proficiency in cloud infrastructure is as crucial as algorithmic knowledge in today’s AI landscape. The initial frustrations with IAM, though challenging, ultimately deepened my understanding of access control and resource management, turning a hurdle into a significant learning opportunity. This hands-on exposure to the entire ML pipeline within a cloud environment has equipped me with a robust skill set essential for future AI projects.
In summary, as AI continues to evolve, the demand for practitioners who can bridge the gap between theoretical knowledge and practical cloud implementation will only grow. This project has been a vital step in that direction, solidifying my foundation in both advanced NLP and cloud-based machine learning. The continuous learning journey in AI is both challenging and incredibly rewarding, and I look forward to exploring its further frontiers.
References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30. https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf