The Computer’s Eyes: From Reality to Numbers
Hello again, all tech enthusiasts and curious minds! Those of you who read my previous post on PyDev might remember how the frustration with paper-based time tracking led to the idea of an automatic login system using facial recognition. It was an exciting step to present the solution and its benefits. But how does it actually work on a technical level? How can a computer ”see” a face and know who it is? In this post, we’ll take a closer look at exactly that, and I promise to keep the language simple even when we touch upon slightly more complex areas. Let’s get started!
It all begins with how a computer represents an image. Unlike our eyes, which perceive a continuous visual scene, a computer sees an image as a collection of small, individual dots called pixels. Imagine a grid where each tiny square has a specific color. In your app, when the camera starts, it captures an image of the face shown in the frame on the screen. This image is essentially a matrix of these pixels.
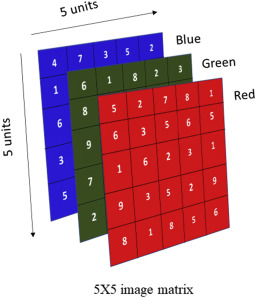
Each pixel in a color image contains information about how much red, green, and blue light it holds – the so-called RGB values. Typically, each color component is represented by a number between 0 and 255. For example, a completely red pixel has the values R=255, G=0, B=0, while a green pixel has R=0, G=255, B=0, and so on. If the image is in grayscale, each pixel is represented by a single value indicating the intensity of gray, from black (0) to white (255).
So, when your app takes a picture of, say, 100×100 pixels, this is stored in the computer’s memory as a large amount of numbers. For a color image, it becomes a three-dimensional matrix of 100x100x3, where each ”layer” represents red, green, and blue, respectively. For a grayscale image, it becomes a simpler 100×100 matrix. It is these numbers that your app then analyzes to find and identify faces. It might feel a bit abstract, but remember that everything displayed on a digital screen is fundamentally translated into these numerical representations.
Finding the Needle in the Haystack: Face Detection
Now that we know how a computer ”sees” an image as a collection of numbers, the next step is to actually find if there is a face within this sea of digits. It’s like looking for a specific shape or pattern in a large amount of data. To do this, your app uses a powerful tool from the Face Recognition library that I mentioned in my last post. The process of face detection usually begins by converting the color image to grayscale. This is done to reduce complexity and improve performance, as the algorithm then only needs to analyze one channel of intensity values instead of three (red, green, blue). Imagine it’s easier to see the contours of a face in a black and white picture than in an image with strong colors that might be distracting.
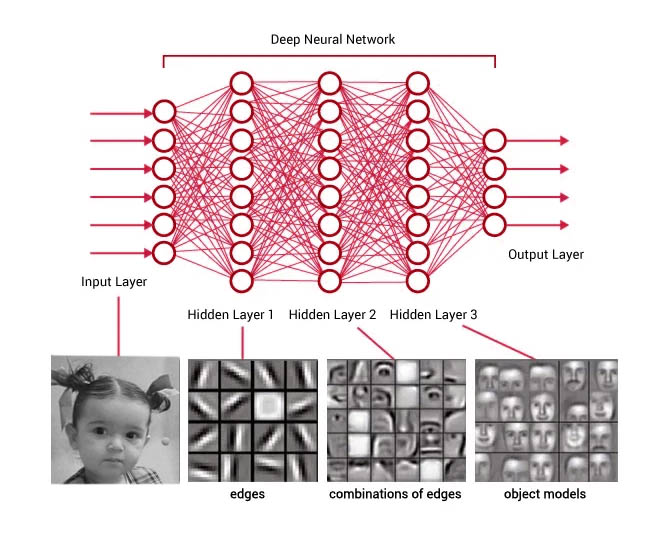
To actually locate where faces are in the image, a CNN model (Convolutional Neural Network) is used. Don’t worry about the complicated name! Think of a CNN as a specialized type of artificial neural network that is very good at finding patterns in visual data. These networks are inspired by how our own brain’s visual cortex works. A neural network consists of several layers of interconnected ”neurons.” Each neuron can be seen as a small computational unit that receives information from the previous layers, processes it, and sends the result to the next layer. In a CNN, certain layers are specialized in detecting simple visual features like edges and corners. The deeper you go into the network, the more complex features it can detect, such as eyes, nose, and mouth, and finally, entire faces.

When an image is passed through the CNN model for face detection, the network analyzes the image pixel by pixel and identifies areas that have the characteristic features of a face. The result of this process is the coordinates for each face found in the image. These coordinates usually specify the position of the top, right, bottom, and left edges of the face. That’s the green rectangle you see in the app when the system has detected a face!
Who Are You?: The Step to Face Recognition
Okay, now we know how the app finds that there’s a face in front of the camera. But how does it know who it is? This is where the magic of face recognition comes in. In your app, you want the system to recognize the employee who is logging in or out. To identify a face, a technique called face embeddings is used. Imagine that each unique face can be represented by a numerical ”fingerprint” or a vector. This vector is a long list of numbers – in the Face Recognition library, it is 128 dimensions long. Each number in this vector represents a specific feature or aspect of the face’s structure and appearance.
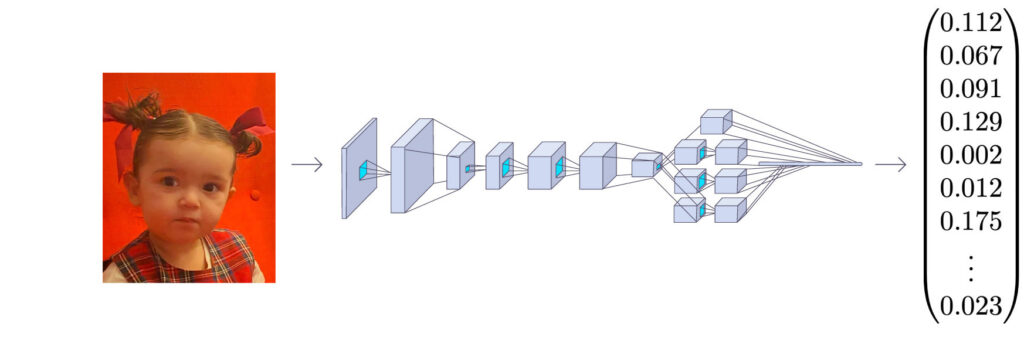
The process of creating this ”fingerprint” starts with the face area detected in the previous step. Here too, a deep neural network trained specifically to generate these face embeddings is used. The network has learned to identify the most important and distinctive features of a face that allow it to be distinguished from other faces, even under different lighting conditions or at different angles.
When an employee registers in your app, a picture of their face is taken, and the system generates such a 128-dimensional vector. This vector is then saved in a database along with information about the employee. This is where the background in Python, AI, and databases you mentioned in your first post truly comes into play! The database in AWS acts as a registry of all approved faces and their unique ”fingerprints.” Then, when someone needs to log in or out, the camera takes a new picture of their face, and the system generates a new face embedding vector in the same way. To determine who it is, this new vector is compared with all the saved vectors in the database.
Finding the Similarities: Comparison with KNN and Euclidean Distance
So how does this comparison happen? One way to do this is using algorithms like K-Nearest Neighbors (KNN). Imagine each face embedding vector as a point in a 128-dimensional space. When a new face appears (a new point), we want to find the K nearest ”neighbors” among the already known faces. If the nearest neighbors belong to the same person in the database, it’s likely that the new face is also that person.
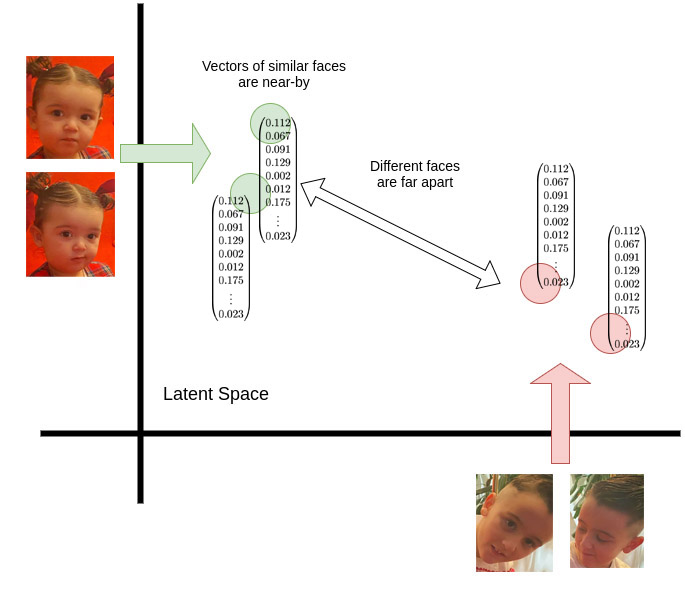
To measure the ”distance” between two face vectors, a mathematical concept called Euclidean distance is often used. In a simpler two-dimensional space (think of a regular map with x and y axes), the Euclidean distance is simply the length of the straight line between two points.
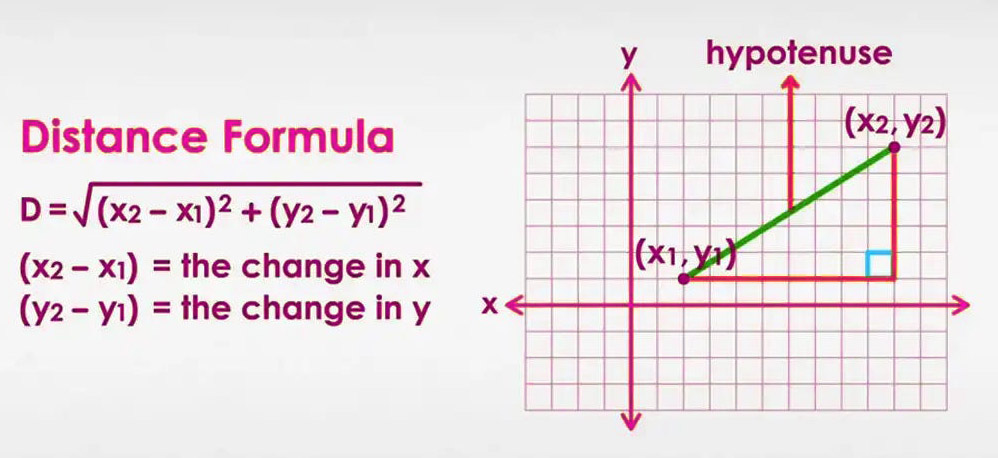
The formula for this is:
d = √((x₁ – x₂)² + (y₁ – y₂)² )
In our case with 128-dimensional vectors, the principle is the same, but the formula is extended to include all 128 dimensions:
d = √((v₁₁ – v₂₁)² + (v₁₂ – v₂₂)² + … + (v₁₁₂₈ – v₂₁₂₈)² )
If the Euclidean distance between the new face vector and a saved vector is sufficiently small, it means the two faces are very similar. The app compares the new vector with all saved vectors, and if it finds a match that falls below a certain threshold value, the person is identified. This is what allows the login and logout in your app to happen so lightning-fast! As a user, you just need to look into the camera, and the system takes care of the rest automatically in the background
Beyond the Details: Neural Networks at Large
We’ve now scratched the surface of how CNNs and deep neural networks are used to detect and recognize faces. But what is the core essence of these networks that makes them so powerful for image processing? As we mentioned earlier, a neural network consists of layers of neurons. In the simplest case, a neuron can be seen as a container holding a number between 0 and 1, called its activation. Think of each neuron lighting up more or less brightly depending on its activation value.
In an image recognition network, the first layer of neurons might correspond to the image’s pixels. The activation in these neurons would then represent, for example, the grayscale value of the corresponding pixel. The last layer in the network has neurons representing the different categories the network has learned to recognize. In the case of face recognition, there could be one neuron for each registered employee. The activation in these output neurons indicates how confident the network is that the input image belongs to that specific category.
Between the first (input layer) and the last (output layer) are hidden layers. It is in these layers that the actual processing and pattern recognition take place. The activations in one layer determine the activations in the next layer. How this happens is governed by weights and biases associated with each connection between neurons in different layers.
Imagine each connection between two neurons has a weight. This weight can be positive or negative and determines how strongly the signal from one neuron affects the next. Additionally, each neuron has a bias, an extra value added to the weighted sum of incoming signals. The bias can be thought of as a threshold that must be exceeded before the neuron becomes active.
By adjusting these weights and biases during training, the network can learn to perform specific tasks, such as recognizing faces. Training involves showing the network a large number of example images (e.g., pictures of different people with correct identifications) and gradually fine-tuning the weights and biases so that the network makes correct predictions. It is precisely this training process that enables AI to offer such accurate predictions.
In the case of your face recognition model, it has been trained on a vast dataset of face images to learn which features are important for distinguishing different individuals and for generating the unique 128-dimensional embedding vectors.
”Understanding” Images: Beyond Classification
While face recognition is a powerful example of image recognition, research in AI and image understanding is constantly advancing. Concepts like CLIP (Contrastive Language-Image Pre-training) aim to create a shared representation of both images and text. The idea behind CLIP is to train a system on an enormous dataset of image-text pairs from the internet. The goal is for the system to learn that images described by a certain text should have similar
”fingerprints” (embeddings) in a common numerical space, while images and texts that do not belong together should have different fingerprints.
This type of training enables AI not only to classify what is in an image (like a cat or a dog) but also to understand the meaning and content of the image in a more nuanced way and connect it to language. For example, a CLIP-trained system can understand that a picture of a ”frog on stilts” actually depicts just that, even if it has never been explicitly trained on that exact combination. Although your current application primarily focuses on face recognition, it’s exciting to think about how similar image understanding techniques could be used in the future to further enhance and expand functionality.
The Way Forward: Continuous Development
As I mentioned in my previous post, this is just the beginning. Development in AI and image recognition is moving at lightning speed. Techniques like Convolutional Neural Networks (CNNs) continue to be fundamental for many applications, including autonomous driving and medical image analysis. At the same time, new methods like Generative Adversarial Networks (GANs) are being explored for generating realistic images and improving image quality.
An important trend is also transfer learning, where pre-trained models are reused on new datasets, saving time and resources. This could be relevant if you want to expand the system in the future to recognize other objects or patterns.
Furthermore, access to large amounts of data and increased computing power plays a crucial role in the development of more advanced image recognition systems. Cloud services like AWS (Amazon Web Services), which your app already uses for the database, provide the necessary infrastructure to train and deploy these complex models. Another exciting area is edge computing, where image recognition models run directly on the device (e.g., in the camera) instead of in the cloud. This enables faster real-time analysis and decision-making, which can be important for applications requiring immediate response.
Concluding Thoughts
I hope this deep dive into how computers see and recognize images has been interesting and has given you a better understanding of the technology behind my face recognition app. From pixels and RGB values to complex neural networks and advanced comparison algorithms – it’s a fascinating journey from physical reality to digital representation and back again.
It’s truly inspiring to see how ideas born from everyday problems can be transformed into innovative solutions using AI. The challenge lies not only in inventing new technology but perhaps even more in applying existing technology to solve concrete problems. And that is precisely what drives me and what I believe will be the major challenge and opportunity within AI in the coming years. Thank you for taking the time to read! And if you have any questions or thoughts, don’t hesitate to leave a comment! See you again soon!